论文阅读07 RDF Shape Induction using Konwledge Base
摘要
知识图谱 (KGs) 正在成为大多数人工智能和认知应用的核心。流行的 KG (如DBpedia和Wikidata) 已经选择RDF数据模型来表示它们的数据。
尽管具有这些优势,但在使用 RDF 数据时仍然存在挑战,例如数据验证。用于在 RDF 数据中指定领域概念化的本体是为蕴含而不是验证而设计的。大多数本体缺乏验证约束所需的粒度信息。
最近在 RDF 形状和诸如 SHACL 和 ShEX 等语言标准化方面的工作为表示 RDF 数据的完整性约束提供了更好的机制。
然而,手动为大型 KG 创建约束仍然是一项繁琐的任务。在本文中,我们提出了一种数据驱动的方法,用于使用数据分析为 RDF 数据引入完整性约束。这些约束可以组合成 RDF 形状,并可用于验证 RDF 图。我们的方法基于机器学习技术,使用概要 RDF 数据作为特征自动生成 RDF 形状。在实验中,提出的方法在为 DBpedia 数据子集推导带有基数约束的 RDF 形状时达到了 97% 的精度。
介绍
知识图谱 (KGs) 正在成为大多数由领域知识驱动的人工智能应用程序的核心。流行的 KG (如DBpedia、YAGO2和Wikidata) 都选择了 RDF 数据模型来表示知识。RDF 是一种基于图的数据模型,它是语义 Web 和关联数据应用程序中的事实上的模型。RDF 图可以使用本体以语义丰富的方式捕获和表示领域信息。
与任何其他数据模型一样,为了指定 RDF 图必须满足的条件,需要施加约束。在实际设置中,约束通常用于三个主要任务:
(a) 指定数据应该持有的属性;
(b) 处理数据内部的矛盾或与考虑中的领域有关的矛盾;
(c) 作为查询优化的帮助。
本体语言设计用于使用已知公理推断新知识,而不是基于公理验证数据。推理器和验证器具有不同的功能,即推理器用于推断新知识,而验证器用于发现违反一组约束的情况。OWL中使用的基础原则,例如使用开放世界假设 (OWA) 和非唯一名称假设,可能会导致验证器中出现意想不到的结果。
因此,使用这些语言执行某些验证任务是很有挑战性的。在大多数传统的数据存储和发布范式中,对预定义模式进行验证是关键步骤之一; 例如,SQL 数据库中的 DDL 约束或 XML 模式或 XML 文档[27]中的RelaxNG 验证。对于 RDF 数据,通常使用基于 OWL 或 RDF Schema 的本体来进行这种验证。
然而,使用本体验证 RDF 数据会导致几个问题:
(a) 预期目的、推断(本体设计的目的)和验证之间的不匹配;
(b) 在大多数本体中缺乏对验证有用的信息。
一般来说,数据质量仍然是获得用户信任的一个关键方面。数据质量与给定上下文中“适合使用”的感知有关[32]。约束是包含在数据上的限制,这些数据应该一直由数据库[2]的实例满足。它们对用户理解数据很有用,因为它们代表了数据自然表现出的特征[22]。数据概要被定义为“为数据库创建小型但有信息的摘要的活动”[17]。在这项研究中,我们提出了一种数据驱动的方法,将机器学习技术应用于概要 RDF 数据,以自动生成完整性约束。
然后,将与特定类相关的一组约束组合在一起,以约束集合的形式生成 RDF Shape。这些 RDF 形状可用于验证 RDF 图。
从数据生成 RDF 形状的主要用例之一是质量评估。在这项工作中,我们使用DBpedia [21](版本201604) 作为我们的目标知识库,并尝试评估 DBpedia 知识库中所有 dbo:Person 实例的质量。这种质量评估的主要需求是确定每个人实例应该遵守的验证规则。例如,一个人的 “dbo:birthDate” 属性应该只有一个值,或者 “dbo:height” 属性的值应该总是一个正数。Person类的实例有超过13000个相关属性(包括 dbo、DBpedia 本体属性和 dbp,从 Wikipedia 信息框键自动生成的属性)。
因此,手动生成此类验证规则是一项繁琐、耗时且容易出错的任务。一些验证规则可以编码到本体中,但是仍然需要大量的手工工作。这项工作提出了一种方法,通过分析数据并使用归纳方法提取这些规则,以 RDF 形状的形式引入此类验证规则。诱导形状的其他用例包括描述数据(这有助于生成查询或创建动态用户界面)。
本文的主要贡献是一种基于使用机器学习算法诱导约束并使用数据概要信息作为特征生成RDF形状的新方法。所提出的方法以适用于任何类型约束的通用方式定义,并使用两种常见约束类型进行验证:
(a)基数约束;
(b)范围约束约束。
问题定义
如果知识图谱不包含冲突或矛盾的数据[16],则将其定义为一致的。当模式具有数据应该遵守的完整性约束时,数据通常会经过验证过程,根据这些约束验证遵从性。
这些完整性约束封装了数据的一致性要求,以便适合给定的用例集。例如,在关系数据库中,完整性约束用数据定义语言 (DDL) 表示,数据库管理系统 (DBMS) 确保插入到数据库中的任何数据不会导致整个数据库中的任何不一致。
然而,RDF数据的验证不是以这种方式进行的,原因有几个,比如缺乏表达约束的语言 (RDFS 和 OWL 是为包含而设计的,而不是像介绍中讨论的那样为验证而设计的),或者具有适合更广泛使用而不适合特定用例的通用模型。
当本体中有定义领域概念化的 TBox 公理时,推理机可以通过验证本体中定义的公理来验证数据集是否与领域一致。然而,大多数本体并没有丰富的公理来帮助检测数据中的不一致性。
大多数大型知识库(如 DBpedia )缺乏完整性约束的定义,手动从头开始创建这些约束定义是一项繁琐的任务。此外,RDF 数据的大多数模式信息只能以最适合包含而不是验证的 OWL 本体的形式提供。然而,大多数使用RDF数据的实际用例需要根据完整性约束进行验证
近年来,W3C 社区通过 RDF 数据形状工作组 (RDF data Shapes Working Group) 和后来的形状表达式社区组 (Shape Expression community Group) 努力标准化一种语言,用于描述RDF实例数据的结构完整性约束和验证规则。这些努力的结果是 W3C 形状约束语言 (SHACL)[19] 和形状表达式语言[26]等语言,它们允许为RDF数据定义完整性约束并验证数据。
然而,对于像 DBpedia 这样包含超过 750 个类和 60,000 个属性 (dbo:和dbp:) 的大型 RDF 知识库,手动生成完整性约束仍然是一个挑战。在这种情况下,本文解决的主要研究问题是:如何为 RDF 数据自动生成完整性约束
在这项研究中,我们提出了一种数据驱动的方法,通过将机器学习技术应用于从数据集中提取的 RDF 数据分析信息,为给定的数据集自动生成 RDF 形状
目标
使用从统计数据分析器中提取的信息,我们的目标是为给定数据集中的数据生成有代表性的 RDF shape。我们在类级别生成形状。示例摘录了SHACL中用于 dbo:Person 类的 RDF Shape 在清单1中。

为此,人们开发了大量专门用于解决此类基于约束的挖掘和学习问题的系统和技术 [10]。约束既可以用于描述性设置,如发现关联规则[3],也可以用于预测性设置,如规则学习[13]。
本文的关键贡献在于,我们研究了如何将剖面图数据应用于RDF形状归纳,据我们所知,还没有针对 RDF 数据验证问题进行处理。
我们的主要假设是,机器学习技术可以通过使用数据分析信息作为特征来生成正确的 RDF 形状。在第4节中,我们定义了一种生成 RDF 形状的方法,并通过评估生成的 RD F形状来验证我们的假设,以确保所定义的约束是准确的 (使用手动标记的测试数据)。
相关工作
本体学习 (OL) 通常被定义为一个包含从数据中自动获取本体知识的技术的领域。因此,范式已经发生了变化,许多方法不再旨在从数据中生成一个完整的、完美标准的本体,而是专注于获取某些形状的公理,如概念定义、原子包容、脱节公理。关于描述逻辑公理的归纳,有一些工作是使用方法完成的,例如: ARM、PGM、SRL、ILP 等。
我们的最终目标与这些研究方法不同。我们的目标不是引入本体论公理,而是引入验证规则。近年来,基于表达约束引入了各种 RDF 验证语言。
Web 本体语言[23]是一种基于描述逻辑 (DL) 的表达本体语言。OWL的语义解决了分布式知识表示场景,在这种场景下,不能假设对领域有完整的知识。为了解决上述不匹配问题,一些方法使用带有封闭世界假设和弱唯一名称假设的 OWL 表达式,这样 OWL 表达式就可以用于验证目的。
W3C 形状约束语言(SHACL)[19]用于根据一组条件验证 RDF 图。这些条件以 RDF 图的形式表示为形状和其他构造。特别是,它有助于通过使用 SPARQL 识别约束。此外,它还提供了高级词汇表来标识谓词及其相关基数和数据类型。
形状表达式 (ShEx)[26] 语言描述 RDF 节点和图结构。节点约束描述 RDF 节点 (IRI、空白节点或文字),形状描述 RDF 图中涉及节点的三元组。这些描述标识谓词及其相关基数和数据类型。
SPARQL推断符号(SPIN)约束将RDF类型或节点与验证规则相关联。特别地,SPIN允许用户使用SPARQL指定规则和逻辑约束。
这些形状表达式语言,即 ShEx、SHACL和SPIN,旨在验证 RDF 数据并在用户之间通信数据语义。它们涵盖了诸如键和基数等约束; 然而,它们的表达能力是有限的,并且需要用户干预。
在我们的方法中,我们的目标是使用机器学习将形状生成过程自动化。更具体地说,可以根据关系模型中的成功程度在 RDF 中设想各种约束,例如基数约束和范围约束。Neuman 和 Merkotte 提出了“特征集”,用于对具有多个连接[25]的 RDF 查询执行基数估计。这些工作与本文的工作在两个轴上有所不同。首先,它们专注于确定每个值的基数,而不是实体-值关系的基数。其次,它们关注查询优化,而不是完整性约束验证。然而,我们利用这些工作的基础,如均值、方差和其他统计特征的分析,导出了完整性约束验证的基数估计方法。
方法
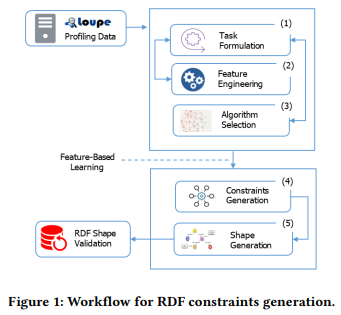
如上所述,RDF 形状可以帮助验证现有的知识图谱;然而,手动完成这是一项乏味的任务。因此,为解决自动生成 RDF 形状的挑战,提出一种基于数据 profiling 的 RDF 形状归纳工作流。我们定义了一个通用的工作流,这样它就可以应用于任何类型的约束。我们为两种类型的约束提供了示例,即基数约束和范围约束。类似地,它可以扩展到其他类型的约束,如值范围约束(min和max值),字符串约束(minLength, maxLength, pattern, languesin, uniqueLanguage),或属性对约束(lessThan, lessThanOrEquals, disjoint, equal)。工作流的目标是通过分析数据模式和统计数据来提取约束,并将提取的约束组合起来生成可用于验证的 RDF 形状。所提议的工作流的主要步骤如图1所示。工作流的输入是来自Loupe[24]的统计分析信息,这是一个用于分析 RDF 数据的工具。
任务制定
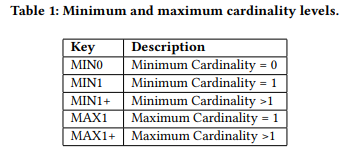
工作流的第一步是作为典型的机器学习任务制定特定的约束提取目标。基数约束:对于基数约束,我们的目标是在相关时生成两个基数约束,即最小基数和最大基数。
作为更好地理解任务的第一步,我们收集了预期的基数(Le。3cixty知识库[33]中的215个属性子集和西班牙国家图书馆(BNE)数据集的166个属性子集。在分析数据集时,我们发现两个数据集中只有少数重复的共同模式。表1显示了我们在黄金标准中发现的常见基数模式。
我们可以在显式表达基数约束的词汇表中观察到同样的趋势。当我们分析链接开放词汇表(LOV)目录中的551个词汇的基数限制值时,猫头鹰:maxCardinality约束的96.91%(875个中的848个)的值为1,猫头鹰:minCardinality约束的93.76%(673个中的631个)的值为0或1。
因此,在我们的工作中,我们不是试图估计最小基数值和最大基数值的确切数字,而是查找每个属性相对于给定类具有哪个基数类别。通过这样做,我们将问题从回归问题减少到分类问题。
范围限制:对于范围限制,我们的目标是双重的。首先,我们希望为与给定类关联的每个属性生成一个对象节点类型约束。我们使用SHACL中已经确定的节点类型的子集,即IRI、Literal、BlankNode和BlankNodeOrIRI。一旦确定了节点类型,就必须确定更具体的范围约束。如果节点类型是Literal,则必须确定相应的数据类型。如果节点类型是IRI、BlankNode或BlankNodeOrIRI,则必须确定对象的类类型。
我们把这个任务也定义为一个分类问题。我们将与给定类的实例关联的每个属性分类为前面提到的节点类型之一。第二项任务是根据数据类型或类类型在与属性关联的对象集中的分布情况,将相应的数据类型或类分配为每个属性的范围。
特征工程
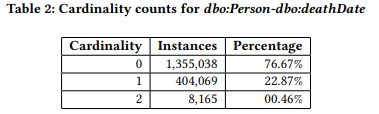
基数约束:Loupe提供基数信息对于与给定类的实例相关联的每个属性。例如,通过分析DBpedia中的1,767,272个dbo:Person实例,Loupe提取dbo:Person-dbo:deathDate组合的基数分布,如表2所示。
在特征工程步骤中,这些原始分析数据用于派生一组可用于预测基数的特征。具体来说,我们从这些数据中推导出了30个特征,包括最小-最大基数、均值、模态、标准差、方差和其他与分布相关的指标。完整的名单可以在这里找到5。范围约束:Loupe为与给定类的实例相关联的每个属性提供了关于IRIs、文字和空白节点数量的统计信息,如表3所示。空节点计数也由Loupe生成,但没有显示在表中,因为本例中没有空节点。
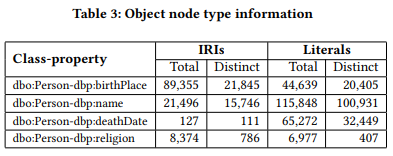
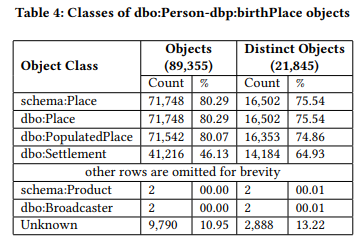
此外,Loupe还通过分析所有IRI和空白节点对象提取对象类型信息。类的所有对象进行分析,表4通过分析dbo:Person-dbp:deathPlace类属性组合的所有对象显示了对象类型信息的示例。它包含对象的数量、每种类类型的不同对象的数量以及它们各自的百分比。可以看到,dbo:Person-dbp:deathPlace的对象使用许多不同的类进行类型化。事实上,大多数对象都是用多个类(例如,等价类、超类)来类型化的。还有一些对象不应该被关联(例如。例如,使用dbp:deathPlace属性,广播器不应该是一个人的死亡地点。此外,还有一些对象的类型信息不可用。
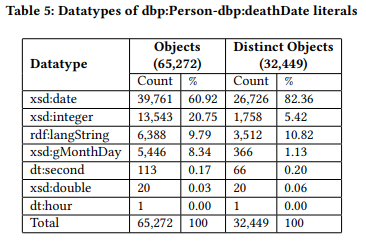
类似地,对于文字对象,Loupe提取关于其数据类型的信息。表5显示了类-属性组合dbp:Person-dbp:deathDate的提取信息示例。对于每种数据类型,它显示了对象的数量、不同对象的数量以及它们相应的百分比。这些信息提供了关于哪些应该是相应的数据类型的启发。
我们使用上述所有信息作为两个任务的特征:检测对象节点类型,检测IRI对象的类类型和文字对象的数据类型。
算法选择
在算法选择步骤中,目标是为第一步中确定的每个任务选择最合适的算法。由于我们已经将基数预测和范围预测任务都表述为分类问题,因此我们将以通用的方式描述算法选择步骤。
为了选择算法,我们将该模型的准确性视为所有预测中正确预测的数量。在经典的机器学习方法中,它被称为分类精度。但是,在训练中运行算法。不同超参数设置的数据集将产生不同的模型[6]。我们特别感兴趣的是选择性能最好的模型。我们使用分类器的准确性来评估各种模型的预测性能。具体而言,评估模型预测性能的步骤如下:
(1)我们希望通过调整学习算法并从给定的假设空间中选择性能最佳的模型来提高分类器的准确性。在我们的概要数据集中,我们观察到在选择约束作为响应变量的情况下,两个变量之间的变化小于15%,很少会发生事件。我们应用SMOTE (Synthetic Minority oversampling Technique)[9]对罕见事件进行过采样。SMOTE函数通过使用自举和k-最近邻对响应变量进行过度采样,以综合创建该响应变量的额外观测值。
(2)为了减少准确性分数的方差,我们需要确保每个实例用于训练的次数相等。我们应用了k倍交叉验证,其中k是在数据集中进行分割的次数。在这种方法中,我们选择k=10的值。这导致将数据集分成10部分(10次折叠)并运行算法10次。
(3)在预测建模问题上建立基线性能是很重要的。在实验分析中,我们采用了ZeroR分类方法。ZeroR是一个平凡的分类器,但它给出了给定数据集性能的下界,这应该通过更复杂的分类器得到显著改善。因此,这是一个合理的测试,可以在不考虑其他属性[34]的情况下预测类的好坏。
(4)最后,为了确定最适合手头问题的机器学习算法,我们对所选算法进行了比较。我们从6类机器学习方法中选择了9种算法。基于分类器精度的最大值,我们从假设空间中选择了性能最好的模型。
约束生成
一旦建立了约束预测模型,就可以生成约束。基数约束:在基数约束的分类任务中,我们确定了五种主要类型的基数类:MINO、MIN1、MIN1+、MAX1、MAX1+。除此之外,MINO和MAX1+没有对数据施加任何约束,这样,任何数据对于这些基数类型都是有效的。因此,如果检测到这些类型,就不会生成约束。对于其他类型,生成相应的SHACL属性约束,如清单2所示。

范围约束:对于范围约束,我们生成两种类型的约束。首先,如果与给定类关联的属性的对象是IRI、Literal、BlankNode和BlankNodeOrIRL,则生成这些节点类型约束如清单3所示。然后,我们为IRI对象生成类类型约束,为文字对象生成数据类型约束。

形状生成
最后一步的目标是组合与给定类相关的所有约束,并为该类生成RDF Shape。在前面的步骤中,为每个类属性组合生成了约束;例如, foaf:name 与 dbo:Person 类关联时的基数约束。类似地,约束生成到与 dbo:Person 类实例关联的所有属性。给定类的所有这些约束组合在一起以生成类的形状。
实验设置
基于我们方法的基数约束,我们在 DBpedia 和 3cixty 两个 KBs 上进行了实验分析。
有趣的是,在给定类的情况下看到基数约束,以及属性,即有多少对象链接到一个主题。如果我们基于属性所表示的关系来考虑主体和对象,我们可以考虑实体-关系(ER)模型所使用的不同基数模式,例如一对一(1-1)、一对多(1-N)、多对一(N-1)和多对多(N-N)。
因此,我们将基数预测任务定义为一个分类问题。这个实验分析的目标是评估我们的方法在多少正确的预测做出的背景下。特别地,我们将基数分类器的性能与基线精度进行比较。更具体地说,在KB图中应用机器学习的核心问题之一是转换和识别特征,同时保留其中包含的信息的微妙之处。我们的目标是验证两个基数约束的预测,即基于黄金标准的概要数据的最小和最大基数。
在这个实验中,我们创建了一个黄金标准,由四个人工注释人员标记数据。批注员互相修改批注,如果没有达成一致意见,就请第三个批注员。对于DBpedia,我们为174个属性的子集创建了期望基数的黄金标准。类似地,对于3cixty,我们为215个属性的子集创建了一个。特别是,收集到的数据集为DBpedia的174个属性和3cixty的215个属性提供了与给定类的实例相关联的每个属性的基数信息。
数据集可以在线访问。我们通过将数据集分成10个部分,对算法部分任务进行10倍交叉验证。对于每个算法训练,它将在90%的数据上运行,并在10%的数据上进行测试。特别地,它将每个数据实例作为训练实例使用9次,每个测试实例使用1次。我们的方法已经实现了一个用R语言编写的原型。