论文阅读03 知识图谱构建技术综述

本周阅读的是《知识图谱构建技术综述》这篇论文,于 2016 年发表于《计算机研究与发展》,是课题组知识图谱研究方向的必读论文之一。本篇综述从技术框架和图谱定义出发,介绍了知识图谱的各类构建技术及其发展历程。以下是重点概念的笔记:
1.知识图谱定义与架构
定义:结构化语义知识库,以符号形式描述物理世界中的概念及其相互关系。
基本组成单位:“实体-关系-实体”三元组,“实体-属性”值对。
研究价值:能够在 Web 网页之上建立概念间的链接关系,从而以最小代价将互联网累计的知识组织起来,成为真正可用的知识。
应用价值:改变现有的“字符串模糊匹配”信息检索方式,通过推理实现真正的概念检索,并以图形化方式向用户展示经过分类整理的结构化知识。
逻辑架构:包括将知识以事实为单位存储在图数据库的数据层,该层以“实体-关系-实体”三元组为事实的基本表达方式,大量数据构成实体关系网络,形成“图谱”;还包括存储经提炼之后的知识的模式层,该层为知识图谱的核心,往往采用本体库来管理该层。
技术架构:知识图谱的构建是不断更新迭代的过程。每轮迭代包括三个阶段:信息抽取、知识融合、知识加工。即可以借助百科网站等结构化数据源以自顶向下的方式构建,也可以从公开数据中提取资源模式,选择置信度高的新模式,以自底向上的方式构建。
2.知识图谱构建技术
2.1.信息抽取
关键问题是如何从异构数据源中自动抽取信息得到候选知识单元。具体涉及到的关键技术包括:实体抽取、关系抽取 、属性抽取。
2.1.1,实体抽取:
也叫命名实体识别(named entity recognition,NER),从文本数据集中自动识别出命名实体,由于实体抽取的质量对后续的知识获取效率及质量影响极大,因此是信息抽取中最为基础和关键的部分。
早起使用基于规则的方法,但有明显局限性,且耗费巨大人力;
随后开始使用统计机器学习的方法辅助解决命名实体抽取问题;最近也开始采用有监督学习与规则结合的方法;
现今,学术界开始关注开放域的信息抽取问题,不在限定于特定知识领域,而面向开放的互联网。建立科学完整的命名实体分类体系也成为了了重要问题。
2.1.2.关系抽取:
经过实体抽取后只能得到离散的命名实体,还需要通过关系抽取提取实体之间的关联关系,才能形成网状知识结构。
早起采用人工构造语法语义规则,模式匹配的方式,有较大的局限性,对规则制定者有较高专业要求,工作量较大;
之后开始使用统计机器学习方法,且近年来逐渐转向半监督和无监督的学习方式;
此外,还有无需预先定义实体关系类型的面向开放域的关系抽取技术,这方面的研究重点是如何提升关系抽取的准确率和召回率,以及对隐含语义关系而非词汇关系的抽取
2.1.3.属性抽取:
属性抽取的目标是从不同信息源中采集特定实体的属性信息,也可以将属性抽取问题转化为名字性的关系抽取问题
当前主要以百科类网站提供的半结构化数据为实体属性抽取研究的数据来源;
如何从海量的非结构化数据中抽取实体属性是值得关注的理论研究问题:一种思路是基于百科类半结构化数据训练出模型,再应用于非结构化数据;另一种思路是基于数据挖掘直接获取实体与属性之间的关系模式。
2.2.知识融合
主要包括知识链接和知识合并,经过知识融合可以消除歧义,剔除冗余和错误概念,从而提升知识质量。
2.2.1.实体链接:
实体链接(entity linking)对于从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。
基本思路是:对于给定实体,从知识库中筛选出一组候选对象,再计算相似度,从而链接到正确实体对象。
基本流程是:从文本中抽取实体,进行实体消歧,和共指消解,连接到对应实体
2.2.1.1.实体消歧:
实体消歧(entity disambiguation)专门用于解决同名实体产生歧义的技术,用于解决某个实体对应于多个实体对象的问题(例:李娜可以指向歌手李娜也可以指向网球运动员李娜)。
聚类法消歧可以将所有指向同一实体对象的指称项聚集到该对象的中心类别之下,常用的方法有:空间向量模型(词袋模型)、语义模型、社会网络模型、百科知识模型等
2.2.1.2.共指消解:
共指消解(entity resolution)用于解决多个指称项对应于同一实体对象的问题(例:在同一篇新闻中,”Barack Obama” 和 “president Obama” 以及 “the president” 等指称项可能指向的是同一个实体对象)
2.2.2.知识合并:
合并外部数据库:数据层融合需要解决实例与关系之间的冲突问题以及冗余问题;模式层融合可将新得到的本体融入已有本体库中。
基本流程为:获取知识、概念匹配、实体匹配、知识评估。
合并关系型数据库:将关系型数据库的数据转换为 RDF 三元组数据,该类技术也可应用于其他半结构化数据。
2.3.知识加工
主要包括:本体构建、知识推理和质量评估。
2.3.1.本体构建:
本体是对概念进行建模的规范,是描述客观世界的抽象模型。
本体反映的知识是一种明确定义的公式,是共享的;本体是树状结构的,相邻层次之间有严格的 “Is A” 关系
2.3.2.知识推理:
知识推理是指从已有实体关系数据出发,经计算机推理得到实体间的新管理,从而拓展和丰富知识网络的过程。
推理方法可以分为:基于逻辑的推理(一阶谓词逻辑、描述逻辑、基于规则的逻辑)和基于图的推理(神经网络模型、Path Ranking 算法)。
2.3.3.质量评估:
质量评估是知识库扣减技术的重要组成部分,引入质量评估可以对知识的可信度进行量化,并通过舍弃置信度较低的知识来保障并提升知识库质量。
2.4.知识更新
知识图谱的构建是不断更新迭代的过程,有两种方式:
全面更新:以更新后的全部数据为输入,从零开始重新构建;特点是操作简单,资源消耗大,维护开销大;
增量更新,以当前新增数据作为输入,向现有图谱中新增;特点是操作复杂,资源消耗小,干预开销大。
3.跨语言知识图谱构建
意义:
- 各语种知识分布不均匀,跨语言构建知识图谱可以弥补单语种知识库的不足;
- 可以充分利用多语种在知识表达方式上的互补性,从而增加知识覆盖率和共享度;
- 通过不同语言对同一知识的表述实现错误信息过滤。
4.知识图谱应用
智能语义搜索应用:对搜索关键字进行解析和推理,映射到图谱中的概念上,再返回图形化的知识结构(如百度、谷歌搜索得到的知识卡片);
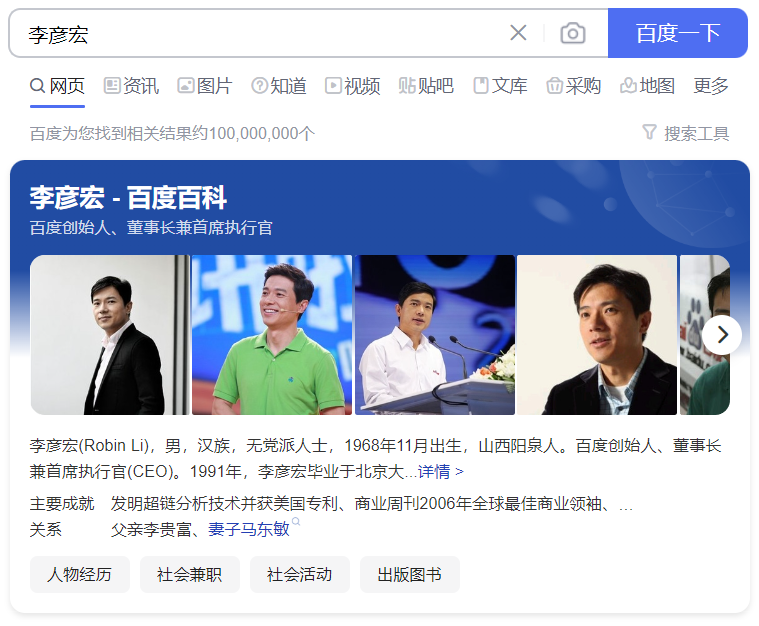
深度问答应用:对问题进行语义分析和语法分析,转化为结构化的查询语句,再在图谱中查询答案(对与知识库中没有答案的情况,采用知识推理技术给出);
5.问题与挑战
- 面向开放域的信息抽取方法仍处于起步阶段;
- 知识融合环节中,如何实现准确的实体链接;
- 知识加工过程中的推理技术亟待突破;
- 知识更新环节严重依赖人工干预;
- 如何解决知识的表达、存储与查询问题。