机器学习05 自监督学习
Self-supervised Learning 自监督学习
Supervised 监督
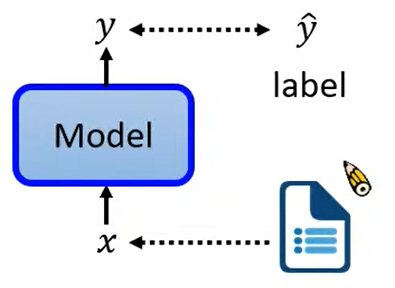
训练数据集是需要标注的,即已知结果的学习过程,通过确定的结果让机器知道学习方向
Self-Supervised 自监督
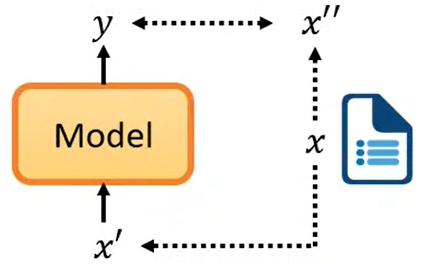
将数据集 x 分为两部分,一部分 x’ 作为输入,另一部分 x” 用于校验输出效果,我们希望模型的输出结果 y 与 x” 越接近越好
BERT
接下来以 BERT 为例,来解释自监督学习
BERT 与 Transformer Encoder 相同
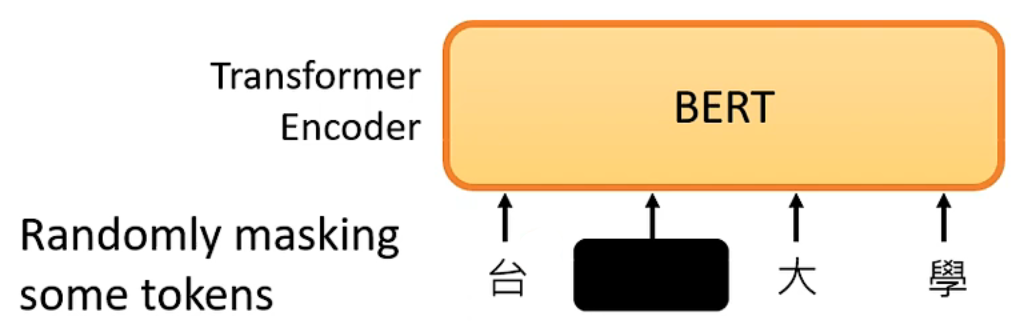
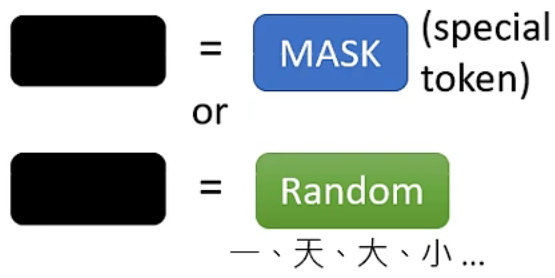
在输入时,我们随机的将输入向量的某个部分遮盖(MASK),可以用特殊标记或或者随机值来进行 MASK
之后,通过这个 Transformer Encoder,我们可以得到一个向量,再将这个向量通过一个 Linear 的 Model 和 softmax层,得到 MASK 部分的预测,由于原输入是已知的,我们不需要再找新的数据集来训练,只需要和原数据作比较就能知道预测结果的好坏
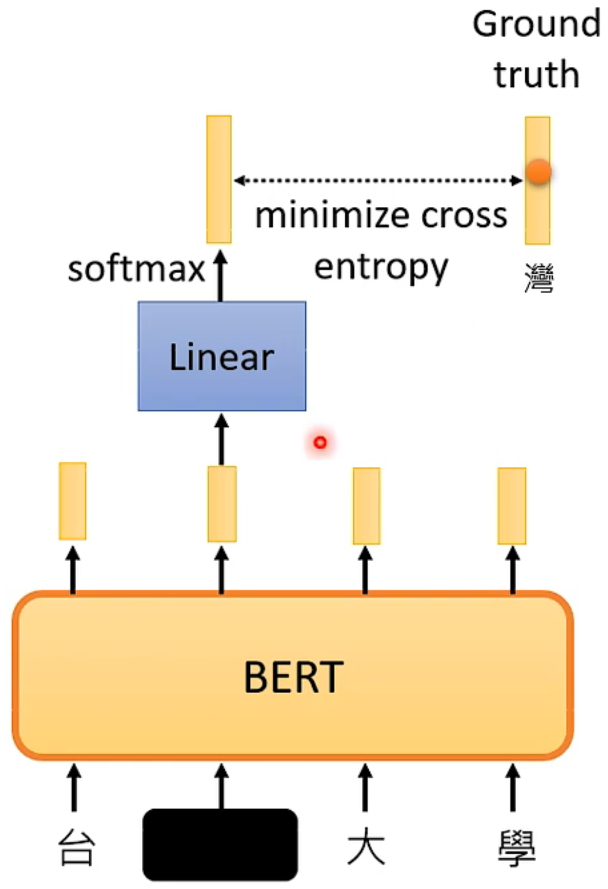
到此为止,BERT 貌似在解决一个“填空”问题,但事实上,BERT 真正的强大之处在于,他可以应用到 下游任务(Downstream Tasks) 上
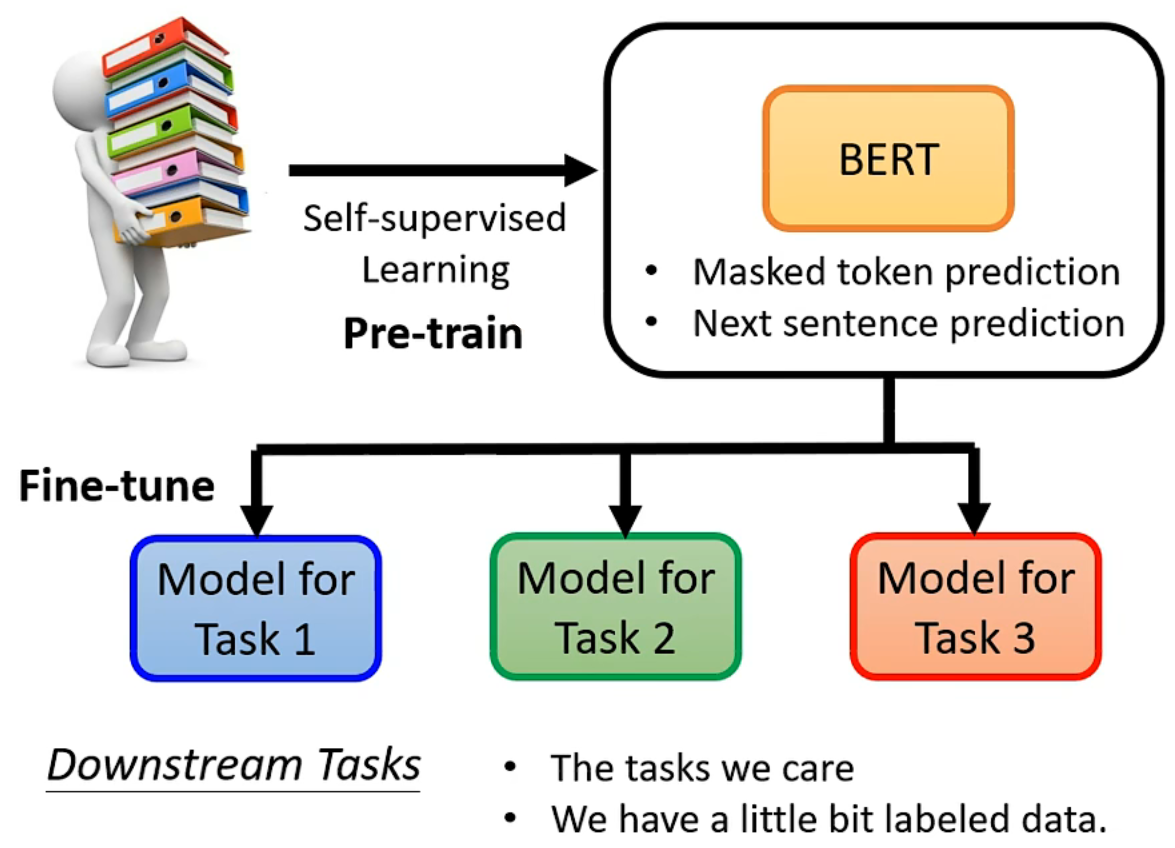
下游任务是我们真正关心的任务,这个任务可能和“填空”没有什么关系,但我们可以用 BERT 这个 预训练 Pre-train 的模型,来帮助解决这些下游任务。
机器学习05 自监督学习
https://username.github.io/2022/08/04/机器学习05-自监督学习/