论文阅读02 TransE
前段时间忙家里各种杂事,只看了师兄给的一篇表示学习综述,大概了解了一下知识图谱和表示学习相关的技术,接下来计划将一些重要模型进一步学习,自己尝试实现一下,这里就以 TransE 作为开头,开个新坑。
TransE 原理
TransE 模型来源于 Translating embeddings for modeling multi-relational data 这篇论文,从标题上不难看出,TransE 将表示学习的过程看做是“翻译”的过程。其基本思想是,将知识三元组中的 relation 看做从 head 到 tail 的翻译过程,如果将这些关系都用向量表示,则应满足
$$
head + relation \approx tail
$$
为了让 relation 的表示能够达到以上要求,TransE 定义了一个距离函数 $d(h + r, t)$来计算头实体和为尾实体之间的距离,原论文使用的是欧氏距离,也可以使用曼哈顿距离。
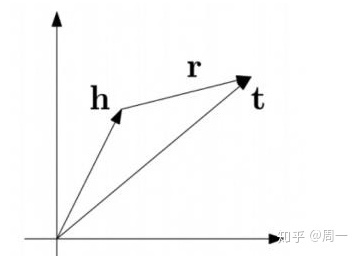
如果成功构建了这样规则下的网络关系,那么就可以根据一个实体和关系来预测另一个实体,或者通过两个实体直接预测它们的关系。
TransE 训练
训练时首先随机生成初始实体向量和关系向量,用于表示知识图谱。整个训练的目的就是求解正确的向量数值,损失函数可以使用 $d(h + r, t)$ 来计算,分为两个方向,正确的三元组应当有更小的 $d$,错误的三元组的 $d$ 则是越大越好。这种方法就是 negative sampling,即相对于负例,正例的得分更高。
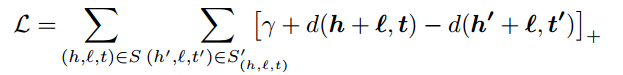
其中 $(h’,l,t’)$ 称为 corrupted triplet,是非同时随机替换头或尾实体得到的负例(也可以替换relation)。$\gamma$ 为 margin。事实上这就是在计算 Soft-margin Loss,可以认为,transE针对给定三元组进行二分类任务,其中负例是通过替换自行构造的,目标是使得最相近的正负例样本距离最大化。